- Why Does Water Expand When It Freezes
- Gold Foil Experiment
- Faraday Cage
- Oil Drop Experiment
- Magnetic Monopole
- Why Do Fireflies Light Up
- Types of Blood Cells With Their Structure, and Functions
- The Main Parts of a Plant With Their Functions
- Parts of a Flower With Their Structure and Functions
- Parts of a Leaf With Their Structure and Functions
- Why Does Ice Float on Water
- Why Does Oil Float on Water
- How Do Clouds Form
- What Causes Lightning
- How are Diamonds Made
- Types of Meteorites
- Types of Volcanoes
- Types of Rocks

Protein Synthesis
Protein synthesis, as the name implies, is the process by which every cell produces specific proteins in its ribosome. In this process, polypeptide chains are formed from varying amounts of 20 different amino acids. It is one of the fundamental biological processes in both prokaryotes and eukaryotes. This is a vital process, as the proteins formed take part in every major cellular activities, ranging from catalysis to forming various structural elements of the cell.
In 1958, Francis Crick proposed a theory called central dogma to describe the flow of genetic information from DNA to RNA to protein. According to this framework, protein is formed from RNA via translation , which in turn, is formed from DNA through transcription.
DNA → RNA → Protein
i. DNA → RNA (Transcription)
ii. RNA → Protein (Translation)
Where and When does Protein Synthesis Take Place
In both prokaryotes and eukaryotes, protein synthesis occurs in the ribosome. That’s why the ribosome is called the ‘protein factory’ of the cell.
However, in eukaryotes , the ribosomes remain scattered in the cytoplasm and are also attached to the Endoplasmic reticulum (RER). So, generally, it is said that, in eukaryotes, the process occurs in the cytoplasm and RER.
On the other hand, in prokaryotes , the ribosomes are scattered throughout the cell cytoplasm. So, commonly, it is said that, in prokaryotes, it takes place in the cytoplasm.
Process: How does it Work
The process of protein synthesis occurs in two steps: transcription and translation. In the first step, DNA is used as a template to make a messenger RNA molecule (mRNA). The mRNA thus formed, exits the nucleus through a nuclear pore and travels to the ribosome for the next step, translation. Upon reaching the ribosome, the genetic code in mRNA is read and used for polypeptide synthesis.
Below is a flowchart of the overall process:
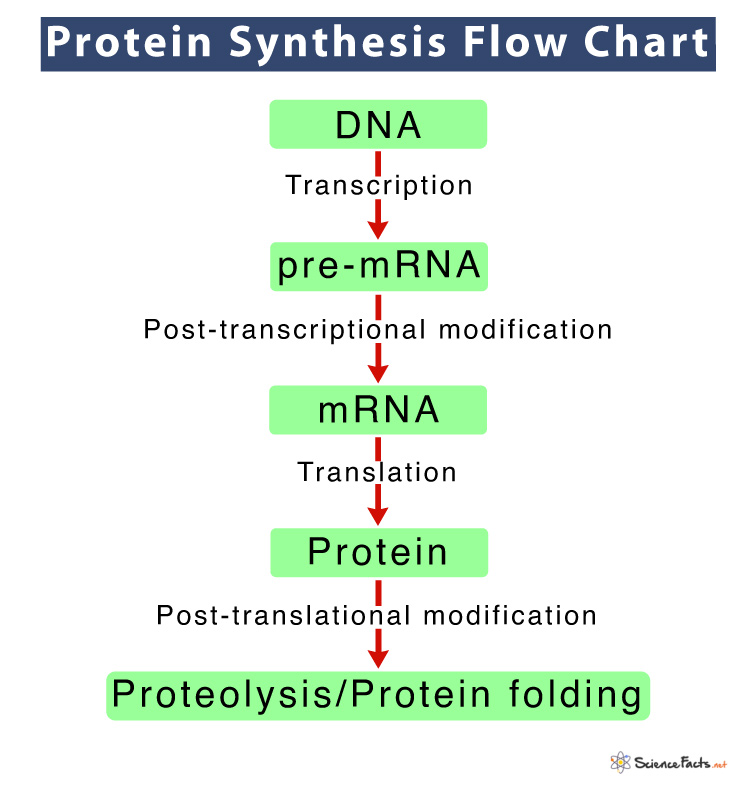
Now, let us discuss these two steps of protein synthesis in detail:
1) Transcription: The First Step of Protein Synthesis
In this process, a single-stranded mRNA molecule is transcribed from a double-stranded DNA molecule. The mRNA thus formed is used as a template for the next step, translation.
The three steps of transcription are: initiation, elongation, and termination.
i) Initiation
The process of transcription begins when the enzyme RNA polymerase binds to a region of a gene called the promoter sequence with the assistance of certain transcription factors. Due to this binding, the double-stranded DNA starts to unwind at the promoter region, forming a transcription bubble. Among the two strands of DNA, one that is used as a template to produce mRNA is called the template, noncoding, or antisense strand. On the other hand, the other one is called the coding or sense strand.
ii) Elongation
After the opening of DNA, the attached RNA polymerase moves along the template strand of the DNA, creating complementary base pairing of that strand to form mRNA. As a result of this, an mRNA transcript containing a copy of the coding strand of DNA is formed. The only exception is, in the mRNA, the nitrogenous base thymine gets replaced by uracil. The sugar-phosphate backbone forms through RNA polymerase.
iii) Termination
Once the mRNA strand is complete, the hydrogen bonds between the RNA-DNA helix break. As a result, the mRNA detaches from the DNA and undergoes further processing.
Post Transcriptional Modification: mRNA Processing
The mRNA formed at the end of the transcription process is called pre-mRNA, as it is not fully ready prepared to enter translation. So, before leaving the nucleus, it needs to undergo some modifications or processing to transform into a mature mRNA. Following these modifications a single gene can produce more than one protein.
a. Splicing
The pre-mRNA is comprised of introns and exons. Introns are the regions that do not code for the protein, whereas exons are the regions that code for the protein.In splicing, noncoding regions or introns of the mRNA get removed under the influence of ribonucleoproteins.
Here, the mRNA gets edited, that is, its some of the nucleotides get changed. For instance, a human protein called Apolipoprotein B (APOB), which helps in lipid transportation in the blood, comes in two different forms due to this editing. One form is smaller than the other because an earlier stop signal gets added in mRNA due to editing.
c. 5’ Capping
In this process, a methylated cap is added to the 5′ end or ‘head’ of the mRNA, replacing the triphosphate group. This cap helps with mRNA recognition by the ribosome during translation, and also protects the mRNA from breaking down.
d. Polyadenylation
At the opposite end of the RNA transcript, that is, to the 3′ end of the RNA chain 30-500 adenines are added, forming the poly A tail. It signals the end of mRNA, and is involved in exporting mRNA from the nucleus.
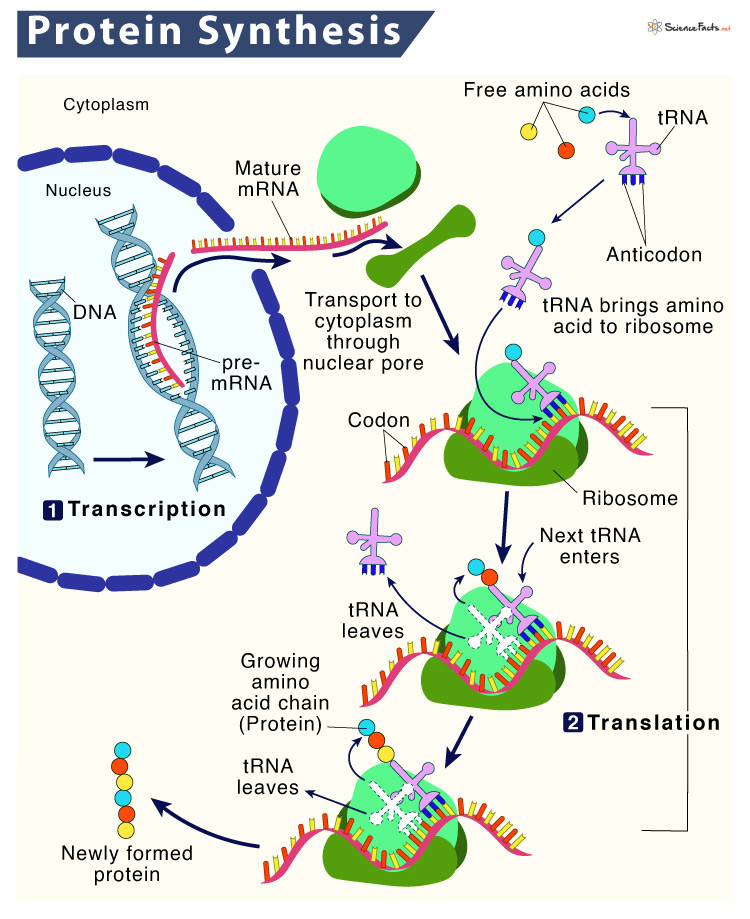
2) Translation: The Second Step of Protein Synthesis
Translation, the next major step of protein synthesis is the process in which the genetic code in mRNA is read to make the amino acids, which are linked together in a particular order based on the genetic code, forming protein.
Similar to transcription, translation also occurs in three stages: initiation, elongation, and termination.
After the mature mRNA leaves the nucleus, it travels to a ribosome. The 5′ methylated cap of the mRNA, containing the strat codon binds to the small ribosomal subunit of the ribosome consisting rRNA. Next, a tRNA containing anticodons complementary to the start codon on the mRNA attaches to the ribosome. These mRNA, ribosome, and tRNA together form an initiation complex.The ribosome reads the sequence of codons in mRNA, and tRNA bring amino acids to the ribosome in the proper sequence.
Once the initiation complex is formed, the large ribosomal subunit of ribosome binds to this complex, releasing initiation factors (IFs). The large subunit of the ribosome has three sites for tRNA binding; A site, P site, and E site. The A (amino acid) site is the region, where the complementary anticodons of aminoacyl-tRNA (tRNA with amino acid) pairs up with the mRNA codon. This ensures that correct amino acid is added to the growing polypeptide chain at the P (polypeptide) site. Once this transfer is complete, the tRNA leaves the ribosome at the E (exit) site and returns to the cytoplasm to bind another amino acid. The whole process gets repeated continuously and the polypeptide chain gets elongated. The rRNA binds the newly formed amino acids via peptide bond, forming the polypeptide chains.
The 3′ poly A tail of the mRNA holds a stop codon that signals to end the elongation stage. A specialized protein called release factor gets attached to the tail o mRNA, causing the entire initiation complex along with the polypeptide chain to break down. As a result, all the components are released.
What Happens Next
After translation, the newly formed polypeptide chain undergoes either of the two post-translational modifications discussed below:
- Proteolysis : Here, the proteins get cleaved, that is, their N-terminal, C-terminal, or the internal amino-acid residues are removed from the polypeptide by the action of proteases.
- Protein folding : In this stage, the nascent proteins get folded to achieve the secondary and tertiary structures.
After these modifications, the protein may bind with other polypeptides or with different types of molecules, such as lipids or carbohydrates, forming lipoproteins or glycoproteins, respectively. Many proteins travel to the Golgi apparatus where they are modified according to their role in cell.
Why is Protein Synthesis Important
As we can see, this complex process of protein synthesis leads to the formation of proteins that plays several crucial roles in cells, including formation of structural components of cell, like cell membrane , cell repair, producing hormones, enzymes, and many more.
Why is it Different in Prokaryotes and Eukaryotes
The speed of protein synthesis is different in prokaryotes and eukaryotes. In prokaryotes, the process is faster, as the whole process takes place in the cytoplasm. On the other hand, in eukaryotes it is slower, as the pre- mRNA is first synthesized in the nucleus and after splicing, the mature mRNA comes to the cytoplasm for translation.
Ans. mRNA carries the coding sequences for protein synthesis from DNA to ribosome. tRNA decodes a specific codon of mRNA and transfers a specific amino acid to the ribosome.
Ans. Three types of RNAs are involved in protein synthesis: messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA).
Ans. Deoxyribonucleic acid (DNA) provides the master code for protein synthesis.
Ans . The codon AUG, coding for methionine starts protein synthesis.
Ans . The two organelles that are involved in protein synthesis are: nucleus and ribosome.
Ans . Well defined reading frames are critical in protein synthesis, because without a well-defined reading frame, the peptide made from a given sequence could be completely different.
Ans . Yes, protein synthesis requires energy.
Ans . Protein synthesis is the process of producing a functional protein molecule based on the information in the genes. On the contrary, DNA replication produces a replica of an existing DNA molecule.
- Protein Synthesis – Flexbooks.ck12.org
- Translation: DNA to mRNA to Protein – Nature.com
- What is protein synthesis – Proteinsynthesis.org
- Translation: Making Protein Synthesis Possible – Thoughtco.com
- Protein Synthesis in the Cell and the Central Dogma – Study.com
Article was last reviewed on Friday, February 17, 2023
Related articles
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Popular Articles
Join our Newsletter
Fill your E-mail Address
Related Worksheets
- Privacy Policy
© 2024 ( Science Facts ). All rights reserved. Reproduction in whole or in part without permission is prohibited.

An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.

StatPearls [Internet].
Biochemistry, protein synthesis.
Jacob E. Hoerter ; Steven R. Ellis .
Affiliations
Last Update: July 17, 2023 .
- Introduction
Our understanding of each of the biological sciences becomes heightened by the study of biochemistry and molecular biology. In the last few decades, advances in laboratory techniques for the study of these microscopic sciences have led us to a greater understanding of the central dogma of molecular biology – that DNA transcribes RNA which then gets translated into protein. Understanding protein synthesis is paramount in studying various medical fields, from the molecular basis of genetic diseases through antibiotic development to expressing recombinant proteins as drugs or clinical laboratory reagents. As one of the foundational concepts in biology, protein synthesis is sufficiently complex that many believe it evolved once, giving the protein synthetic machinery in all organisms on the planet a common ancestry. Despite having certain underlying similarities in their mechanism, protein synthesis in the three major lines of descent (bacteria, archaea, and eukaryotes) has diverged to the point that substantive mechanistic differences have arisen. These differences have been exploited in nature as organisms produce compounds targeting the protein synthetic machinery of competitors as they vie for limited resources. Science has modified many of these compounds that target the machinery for protein synthesis in pathogenic microbes for use in the clinic as antibiotics. As our understanding of the mechanisms of protein synthesis continues to grow, there will likely be countless additional applications for this knowledge in medicine, research, and industry.
- Fundamentals
Protein synthesis involves a complex interplay of many macromolecules.
- The eukaryotic ribosome has two subunits: a 40S small subunit and a 60S large subunit. Together, the eukaryotic ribosome is 80S. There are several sites of functional significance, but the most important ones are the A (aminoacyl), P (peptidyl), and E (exit) sites. The eukaryotic ribosome is a ribonucleoprotein complex composed of 4 RNAs and 80 proteins. Many of the functions of the ribosome, including catalyzing peptide bond formation, are attributed to ribosomal RNA (rRNA) rather than ribosomal proteins, which instead play a primary role in subunit assembly. Ribosomes can be found either adherent to membranes of the endoplasmic reticulum or free within the cytoplasm. [1]
- Bacterial ribosomes have two subunits, 30S and 50S, that join to form a 70S particle. In general, bacterial ribosomes are smaller than their eukaryotic counterparts, including fewer ribosomal proteins (55) and shorter rRNAs (3 in total). Certain regions of rRNA and some of the ribosomal proteins remain conserved between bacteria and eukaryotes. Other regions of rRNA and proteins are unique to either eukaryotes or bacteria and account in part for differences in mechanisms of protein synthesis discussed above.
- Eukaryotic cells contain a second type of ribosome found within the mitochondrion, which maintains a system of protein synthesis distinct from that found in the cytoplasm. Despite their presence in eukaryotic cells, the origins of the mitochondrial ribosome are traceable to bacteria, consistent with the endosymbiont theory of mitochondrial origins. Care must be taken during antibiotic development to avoid targeting characteristics of the mitochondrial ribosome shared with bacterial ribosomes.
- Messenger RNA (mRNA): the mRNA is another type of ribonucleic acid that functions to carry the coding section of a gene for protein synthesis. It contains portions of non-coding and coding sequences. The coding sequence groups nucleotides into codons, which are three specific nucleotides that correspond to a particular amino acid specified by the genetic code. [2]
- Transfer RNA (tRNA): tRNAs are adaptors bridging the nucleotide sequence found in mRNAs to the amino acid sequence found in a growing protein. Transfer RNAs assume a cloverleaf-like secondary structure with an amino acid linked to its 3’ end through an ester linkage and a stretch of three nucleotides at the base of the cloverleaf referred to as the anticodon. The three bases of the anticodon base pair with complementary codon sequences in an mRNA during the process of protein synthesis. This base-pairing interaction plays a critical role in the readout of the genetic code from mRNA to protein. There are 20 different aminoacyl-tRNA synthetases, one for each of the 20 common amino acids. Once an amino acid links to its cognate tRNA it is referred to as an aminoacyl tRNA, or “charged” tRNA. [3]
- Genetic code: The genetic code sequence is three nucleotides originally encoded an organism’s genome that specifies individual amino acids found in proteins. There are 20 common amino acids used by the protein synthetic machinery and 64 potential sequence permutations of the four bases used to specify the 20 amino acids. Early studies revealed that the code was degenerate, with many of the amino acids specified by multiple 3-base combinations. In general, when multiple codons specify a single amino acid, degeneracy is found at the third or “wobble” position. [1] Sixty-one of the 64 sequence permutations specify amino acids, whereas three of the sequence permutations serve as “stop” codons to terminate protein synthesis. While initially thought to be the same for all living organisms, scientists now know that there are a small number of deviations from the universal code found in mitochondria and specific bacterial species.
- Genetic code and human disease: Appropriate readout of the genetic code is essential for human health. Mutations that alter protein-coding sequences can affect proteins in many different ways. The effect of mutations on the coding sequence can classify as either synonymous or nonsynonymous depending on whether they are predicted to alter the primary structure of a protein.
- Synonymous mutations relate to the degeneracy of the code and the fact that changes in base sequence may not have an effect on which amino acid a codon represents (though it should be noted that some synonymous mutations may affect pre-mRNA splicing and so influence a protein’s primary structure). Synonymous mutations typically fall in the third position of a codon.
- Nonsynonymous mutations fall into three different classes:
- Missense mutations where there is substitution of one amino acid for another.
- Nonsense mutations which introduce a premature termination codon in an mRNA sequence. These mutations typically result in a truncated protein.
- Frameshift mutations result from insertion or deletion mutations that shift the reading frame of a coding sequence such that sequencing downstream of the mutational event no longer code for the correct amino acid sequence of a protein.
- Protein factors– the process of protein synthesis requires multiple non-ribosomal proteins that transiently participate during the initiation, elongation, and termination phases of protein synthesis. These factors are named for the phase in which they function (for example, eukaryotic initiation factor 2, eIF2). [2]
- Issues of Concern
The proteins that a cell expresses are the ultimate manifestation of its phenotype. Cells within tissues of the human body have variable phenotypic expression involved in defining tissue organization and function despite having identical genomes due to the differential expression of genes within the genome. While the differential regulation of gene expression primarily occurs at the level of transcription, regulation of gene expression can also take place at the post-transcriptional level, including regulated translation. Because of the importance of protein expression to the phenotypic properties of a cell, errors in the cellular proteome manifested at all levels of the correct readout of genetic information from gene to protein can have broad implications on health.
- Cellular Level
The eukaryotic cell is compartmentalized, with different cellular compartments defined by biological membranes. The synthesis of components of the translational machinery begins with the transcription of mRNAs, tRNAs, and rRNAs in the nucleus by RNA polymerases II, III, and I, respectively. Transfer RNAs and the mRNAs encoding ribosomal proteins exit the nucleus and the latter get translated in the cytoplasm. Ribosomal proteins then return to the nucleus where they assemble hierarchically on rRNAs being transcribed by RNA polymerase I. This assembly process defines a compartment of nucleus referred to as the nucleolus. Ribosome assembly is a complex process involving hundreds of accessory factors that transiently associate with ribosomal subunits during their maturation. While most of the steps involved in maturing ribosomal subunits occur within the nucleolus before the subunits exiting through nuclear pores, final steps in subunit maturation occur in the cytoplasm. Ribosomes translating most cellular mRNAs do so as free ribosomes in the cytoplasm. In contrast, ribosomes translating mRNAs encoding proteins destined for secretion from the cell or resident proteins of the endoplasmic reticulum, Golgi apparatus, lysosome, or plasma membrane get localized to the endoplasmic reticulum membrane. [4]
Briefly, translation can be broken down into three phases initiation, elongation, and termination. Initiation consists of identifying the exact site in the sequence of nucleotides in an mRNA to begin translation. This process has significant differences between eukaryotes (described here) and prokaryotes. Upon identification of the start site for translation, elongation ensues as the ribosome moves along the mRNA “reading” groups of three nucleotides that specify each amino acid added to the growing polypeptide chain. Finally, termination occurs when the ribosome encounters one of three termination codons, and the completed protein gets released from the ribosome.
Translation begins with the assembly of an 80S initiation complex on mRNA. This process involves identifying appropriate codon to initiate translation. The AUG codon specifies the amino acid methionine and virtually all proteins specified by the genetic code begin with methionine. In eukaryotes, the AUG used to initiate protein synthesis is usually the first AUG downstream of the cap structure, found at the 5’ end of the mRNA. A protein complex known as eIF4F recognizes the cap structure. The eIF4F complex then recruits the 43S pre-initiation complex comprised of 40S subunits together with a ternary complex formed of the initiator tRNA (Met-tRNA), eIF2, and GTP to the 5’ end of an mRNA. The 40S complex subsequently scans down the mRNA until encountering the first AUG and the 48S initiation complex forms. In addition to eIF4F and eIF2, multiple other initiation factors facilitate the formation of the 48S initiation complex. At this point, the 60S ribosomal subunit joins the 48S initiation complex, all initiation factors are released, and the elongation phase of translation is set to begin. In the 80S initiation complex, the initiator Met-tRNA is base-paired to the initiating AUG in the ribosomal P site with the next codon of the mRNA positioned in the ribosomal A site. Translational re-initiation facilitation occurs by the interaction of the eIF4F complex with both the 5’ cap and the 3’ polyA tail of an mRNA. [5]
As with initiation, elongation requires the use of non-ribosomal proteins known as elongation factors. Eukaryotic EF1A (eEF1A) forms ternary complexes with aminoacyl-tRNAs and GTP. These ternary complexes enter the empty A site of the ribosome and if an appropriate codon-anticodon interaction forms between the incoming aminoacyl-tRNA and the codon in the A site, GTP will be hydrolyzed and eEF1A released. At this point, the peptidyl-transferase site of the ribosome catalyzes peptide bond formation as the free amino group of the incoming aminoacyl-tRNA attacks the ester bond linking the growing polypeptide to the tRNA in the ribosomal P site. The resultant uncharged tRNA occupying the P site moves to the E (exit) site and leaves the ribosome. The growing polypeptide chain previously in the P site is now elongated by one amino acid as it transfers to the aminoacyl-tRNA in the A site. The peptidyl-tRNA in the A site is then translocated to back to the P site with the help of eEF2 and GTP. The A site is now empty, and the entire process is repeated over and over again as the ribosome moves down the mRNA.
Termination occurs when eRF1, a release factor structurally analogous to tRNA, recognizes termination codons in an mRNA and recruits eRF3 to hydrolyze the polypeptide chain from the tRNA occupying the P site. Termination of translation completes by the dissociation of the ribosomal subunits, which are now capable of initiating another round of protein synthesis. Multiple ribosomes can translate a single mRNA simultaneously forming complexes known as polysomes. [5] [6] [7]
There are many possible methods of confirming that a particular protein is being synthesized.
Immunostaining
Because of the large number of proteins synthesized in a typical cell, verifying the presence of a particular protein is understandably challenging. One way to confirm the presence of a specific protein in a clinical specimen is through immunostaining. This technique introduces an antibody to a protein of interest, and the exquisite specificity of the antibody serves for protein detection.
In immunostaining, the specimen is incubated with a primary antibody solution. This antibody can contain a fluorescent molecule on its heavy chain or an enzyme (such as horseradish peroxidase) that will fluoresce in the presence of a suitable substrate. The light released can be visualized under a microscope or exposed to photosensitive film in a dark room for later development. Immunostaining can either be direct where the primary antibody possesses the means of fluorescent detection or indirect, where a secondary antibody raised against the primary antibody is detectable via fluorescence. [8]
Protein Electrophoresis
As with nucleic acids, proteins can be separated based on size and/or charge using gel electrophoresis. Proteins can be run in their native configurations or undergo denaturing before electrophoresis. In denaturing electrophoresis, a detergent such as sodium dodecyl sulfate (SDS) is used to disrupt non-covalent bonding forces within proteins. SDS also gives proteins common charge to mass ratios, so the only force operating during SDS-polyacrylamide gel electrophoresis is the molecular sieving action of the polyacrylamide gel. Proteins separated in this manner can be detected either non-specifically with dyes like coomassie blue or specifically using antibodies in a procedure referred to as Western blotting or immunoblotting.
- Pathophysiology
Many human diseases result from changes in protein sequence caused by mutations that alter the correct readout of genetic information from gene to a functional protein. Defects in the protein synthetic machinery also cause a small but growing number of human diseases. Examples of such pathologies follow.
Sickle Cell Anemia
Human hemoglobin contains two alpha and two beta chains to create a heterotetramer. In Sickle Cell Anemia, the sixth codon of the beta chain contains a missense mutation, in which glutamic acid, a charged amino acid, is replaced with valine, a neutral amino acid. This single amino acid difference affects the tertiary and quaternary structures of hemoglobin such that it distorts the biconcave shape of erythrocytes into sickle shapes in certain conditions. [9]
Duchenne Muscular Dystrophy
Like many X-linked diseases, DMD primarily affects males at an early age. It is characterized clinically by muscle weakness, calf pseudohypertrophy, and the Gower sign in a child. One of the pathophysiologic origins of this disease is the formation of a premature stop codon in an early exon of the dystrophin gene, which leads to a truncated dystrophin protein which compromises the integrity of the sarcomere and contractile function of the muscle. [10]
Diamond-Blackfan Anemia
While many human diseases result from mutations in the coding sequences of genes that affect protein production, Diamond-Blackfan anemia (DBA) is one of a growing number of conditions resulting from defects in the protein synthetic machinery. DBA is caused by autosomal dominant mutations in genes encoding proteins of either the 40S or 60S ribosomal subunit. While the exact mechanisms underlying the pathophysiology of DBA are currently unknown, it seems likely that changes in cellular proteomes (the protein composition of a cell) resulting from suboptimal numbers of ribosomes contribute in part to the clinical features of the disease. These clinical features include a deficit in red blood cell production, small size, and a heterogeneous number of congenital anomalies. [11]
- Clinical Significance
The clinical significance of protein synthesis lies not only in human translation but in differences between human and bacterial translation. The bacterial ribosome (70S) has the same core components and many structurally similar sites compared to the eukaryotic ribosome (80S). However, translational differences between humans and bacteria create targets for antimicrobial drugs. These differences allow certain antibiotics to bind selectively to bacterial ribosomes at low concentrations, targeting bacteria selectively and either inhibiting growth or killing the microbe. Several commonly prescribed antibiotics target specific components of the bacterial ribosome and mRNA. Aminoglycosides target the 30S small ribosomal subunit; specifically, this class binds to the rRNA segment active in the A site. The tetracyclines operate similarly by competing for the A site with charged aminoacyl tRNA. The macrolide antibiotics act on the 50S large ribosomal subunit. When they bind to the rRNA of the large subunit, it prevents the formation of the peptide bond and promotes the early expulsion of the tRNA in the P site. [12] [3]
The clinical manifestations of differences in protein synthesis can also be useful in diagnosis. Native protein electrophoresis can help identify hemoglobinopathies in newborn screenings. Similarly, serum protein electrophoresis can identify characteristic M protein spikes of monoclonal protein expression in multiple myeloma.
- Review Questions
- Access free multiple choice questions on this topic.
- Comment on this article.
Disclosure: Jacob Hoerter declares no relevant financial relationships with ineligible companies.
Disclosure: Steven Ellis declares no relevant financial relationships with ineligible companies.
This book is distributed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) ( http://creativecommons.org/licenses/by-nc-nd/4.0/ ), which permits others to distribute the work, provided that the article is not altered or used commercially. You are not required to obtain permission to distribute this article, provided that you credit the author and journal.
- Cite this Page Hoerter JE, Ellis SR. Biochemistry, Protein Synthesis. [Updated 2023 Jul 17]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.
In this Page
Bulk download.
- Bulk download StatPearls data from FTP
Related information
- PMC PubMed Central citations
- PubMed Links to PubMed
Similar articles in PubMed
- Review An Experimental Approach to Genome Annotation: This report is based on a colloquium sponsored by the American Academy of Microbiology held July 19-20, 2004, in Washington, DC [ 2004] Review An Experimental Approach to Genome Annotation: This report is based on a colloquium sponsored by the American Academy of Microbiology held July 19-20, 2004, in Washington, DC . 2004
- Review The Global Genome Question: Microbes as the Key to Understanding Evolution and Ecology: This report is based on a colloquium, “The Global Genome Question: Microbes as the Key to Understanding Evolution and Ecology,” sponsored by the American Academy of Microbiology and held October 11-13, 2002, in Longboat Key, Florida [ 2004] Review The Global Genome Question: Microbes as the Key to Understanding Evolution and Ecology: This report is based on a colloquium, “The Global Genome Question: Microbes as the Key to Understanding Evolution and Ecology,” sponsored by the American Academy of Microbiology and held October 11-13, 2002, in Longboat Key, Florida . 2004
- Japan-China Joint Medical Workshop on Drug Discoveries and Therapeutics 2008: The need of Asian pharmaceutical researchers' cooperation. [Drug Discov Ther. 2008] Japan-China Joint Medical Workshop on Drug Discoveries and Therapeutics 2008: The need of Asian pharmaceutical researchers' cooperation. Nakata M, Tang W. Drug Discov Ther. 2008 Oct; 2(5):262-3.
- Review Translational Metabolomics of Head Injury: Exploring Dysfunctional Cerebral Metabolism with Ex Vivo NMR Spectroscopy-Based Metabolite Quantification. [Brain Neurotrauma: Molecular, ...] Review Translational Metabolomics of Head Injury: Exploring Dysfunctional Cerebral Metabolism with Ex Vivo NMR Spectroscopy-Based Metabolite Quantification. Wolahan SM, Hirt D, Glenn TC. Brain Neurotrauma: Molecular, Neuropsychological, and Rehabilitation Aspects. 2015
- Chronoastrobiology: proposal, nine conferences, heliogeomagnetics, transyears, near-weeks, near-decades, phylogenetic and ontogenetic memories. [Biomed Pharmacother. 2004] Chronoastrobiology: proposal, nine conferences, heliogeomagnetics, transyears, near-weeks, near-decades, phylogenetic and ontogenetic memories. Halberg F, Cornélissen G, Regal P, Otsuka K, Wang Z, Katinas GS, Siegelova J, Homolka P, Prikryl P, Chibisov SM, et al. Biomed Pharmacother. 2004 Oct; 58 Suppl 1:S150-87.
Recent Activity
- Biochemistry, Protein Synthesis - StatPearls Biochemistry, Protein Synthesis - StatPearls
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
This page has been archived and is no longer updated
Translation: DNA to mRNA to Protein
The genes in DNA encode protein molecules, which are the "workhorses" of the cell , carrying out all the functions necessary for life. For example, enzymes, including those that metabolize nutrients and synthesize new cellular constituents, as well as DNA polymerases and other enzymes that make copies of DNA during cell division , are all proteins.
In the simplest sense, expressing a gene means manufacturing its corresponding protein, and this multilayered process has two major steps. In the first step, the information in DNA is transferred to a messenger RNA ( mRNA ) molecule by way of a process called transcription . During transcription , the DNA of a gene serves as a template for complementary base-pairing , and an enzyme called RNA polymerase II catalyzes the formation of a pre-mRNA molecule, which is then processed to form mature mRNA (Figure 1). The resulting mRNA is a single-stranded copy of the gene, which next must be translated into a protein molecule.
Where Translation Occurs
Within all cells, the translation machinery resides within a specialized organelle called the ribosome . In eukaryotes, mature mRNA molecules must leave the nucleus and travel to the cytoplasm , where the ribosomes are located. On the other hand, in prokaryotic organisms, ribosomes can attach to mRNA while it is still being transcribed. In this situation, translation begins at the 5' end of the mRNA while the 3' end is still attached to DNA.
In all types of cells, the ribosome is composed of two subunits: the large (50S) subunit and the small (30S) subunit (S, for svedberg unit, is a measure of sedimentation velocity and, therefore, mass). Each subunit exists separately in the cytoplasm, but the two join together on the mRNA molecule. The ribosomal subunits contain proteins and specialized RNA molecules—specifically, ribosomal RNA ( rRNA ) and transfer RNA ( tRNA ) . The tRNA molecules are adaptor molecules—they have one end that can read the triplet code in the mRNA through complementary base-pairing, and another end that attaches to a specific amino acid (Chapeville et al. , 1962; Grunberger et al. , 1969). The idea that tRNA was an adaptor molecule was first proposed by Francis Crick, co-discoverer of DNA structure, who did much of the key work in deciphering the genetic code (Crick, 1958).
Within the ribosome, the mRNA and aminoacyl-tRNA complexes are held together closely, which facilitates base-pairing. The rRNA catalyzes the attachment of each new amino acid to the growing chain.
The Beginning of mRNA Is Not Translated
Interestingly, not all regions of an mRNA molecule correspond to particular amino acids. In particular, there is an area near the 5' end of the molecule that is known as the untranslated region (UTR) or leader sequence. This portion of mRNA is located between the first nucleotide that is transcribed and the start codon (AUG) of the coding region, and it does not affect the sequence of amino acids in a protein (Figure 3).
So, what is the purpose of the UTR? It turns out that the leader sequence is important because it contains a ribosome-binding site. In bacteria , this site is known as the Shine-Dalgarno box (AGGAGG), after scientists John Shine and Lynn Dalgarno, who first characterized it. A similar site in vertebrates was characterized by Marilyn Kozak and is thus known as the Kozak box. In bacterial mRNA, the 5' UTR is normally short; in human mRNA, the median length of the 5' UTR is about 170 nucleotides. If the leader is long, it may contain regulatory sequences, including binding sites for proteins, that can affect the stability of the mRNA or the efficiency of its translation.
Translation Begins After the Assembly of a Complex Structure
Table 1 shows the N-terminal sequences of proteins in prokaryotes and eukaryotes, based on a sample of 170 prokaryotic and 120 eukaryotic proteins (Flinta et al. , 1986). In the table, M represents methionine, A represents alanine, K represents lysine, S represents serine, and T represents threonine.
Table 1: N-Terminal Sequences of Proteins
* Methionine was removed in all of these proteins
** Methionine was not removed from any of these proteins
Once the initiation complex is formed on the mRNA, the large ribosomal subunit binds to this complex, which causes the release of IFs (initiation factors). The large subunit of the ribosome has three sites at which tRNA molecules can bind. The A (amino acid) site is the location at which the aminoacyl-tRNA anticodon base pairs up with the mRNA codon, ensuring that correct amino acid is added to the growing polypeptide chain. The P (polypeptide) site is the location at which the amino acid is transferred from its tRNA to the growing polypeptide chain. Finally, the E (exit) site is the location at which the "empty" tRNA sits before being released back into the cytoplasm to bind another amino acid and repeat the process. The initiator methionine tRNA is the only aminoacyl-tRNA that can bind in the P site of the ribosome, and the A site is aligned with the second mRNA codon. The ribosome is thus ready to bind the second aminoacyl-tRNA at the A site, which will be joined to the initiator methionine by the first peptide bond (Figure 5).
The Elongation Phase
Next, peptide bonds between the now-adjacent first and second amino acids are formed through a peptidyl transferase activity. For many years, it was thought that an enzyme catalyzed this step, but recent evidence indicates that the transferase activity is a catalytic function of rRNA (Pierce, 2000). After the peptide bond is formed, the ribosome shifts, or translocates, again, thus causing the tRNA to occupy the E site. The tRNA is then released to the cytoplasm to pick up another amino acid. In addition, the A site is now empty and ready to receive the tRNA for the next codon.
This process is repeated until all the codons in the mRNA have been read by tRNA molecules, and the amino acids attached to the tRNAs have been linked together in the growing polypeptide chain in the appropriate order. At this point, translation must be terminated, and the nascent protein must be released from the mRNA and ribosome.
Termination of Translation
There are three termination codons that are employed at the end of a protein-coding sequence in mRNA: UAA, UAG, and UGA. No tRNAs recognize these codons. Thus, in the place of these tRNAs, one of several proteins, called release factors, binds and facilitates release of the mRNA from the ribosome and subsequent dissociation of the ribosome.
Comparing Eukaryotic and Prokaryotic Translation
The translation process is very similar in prokaryotes and eukaryotes. Although different elongation, initiation, and termination factors are used, the genetic code is generally identical. As previously noted, in bacteria, transcription and translation take place simultaneously, and mRNAs are relatively short-lived. In eukaryotes, however, mRNAs have highly variable half-lives, are subject to modifications, and must exit the nucleus to be translated; these multiple steps offer additional opportunities to regulate levels of protein production, and thereby fine-tune gene expression.
References and Recommended Reading
Chapeville, F., et al. On the role of soluble ribonucleic acid in coding for amino acids. Proceedings of the National Academy of Sciences 48 , 1086–1092 (1962)
Crick, F. On protein synthesis. Symposia of the Society for Experimental Biology 12 , 138–163 (1958)
Flinta, C., et al . Sequence determinants of N-terminal protein processing. European Journal of Biochemistry 154 , 193–196 (1986)
Grunberger, D., et al . Codon recognition by enzymatically mischarged valine transfer ribonucleic acid. Science 166 , 1635–1637 (1969) doi:10.1126/science.166.3913.1635
Kozak, M. Point mutations close to the AUG initiator codon affect the efficiency of translation of rat preproinsulin in vivo . Nature 308 , 241–246 (1984) doi:10.1038308241a0 ( link to article )
---. Point mutations define a sequence flanking the AUG initiator codon that modulates translation by eukaryotic ribosomes. Cell 44 , 283–292 (1986)
---. An analysis of 5'-noncoding sequences from 699 vertebrate messenger RNAs. Nucleic Acids Research 15 , 8125–8148 (1987)
Pierce, B. A. Genetics: A conceptual approach (New York, Freeman, 2000)
Shine, J., & Dalgarno, L. Determinant of cistron specificity in bacterial ribosomes. Nature 254 , 34–38 (1975) doi:10.1038/254034a0 ( link to article )
- Add Content to Group
Article History
Flag inappropriate.


Email your Friend

- | Lead Editor: Bob Moss

Within this Subject (34)
- Applications in Biotechnology (4)
- Discovery of Genetic Material (4)
- DNA Replication (6)
- Gene Copies (5)
- Jumping Genes (4)
- RNA (7)
- Transcription & Translation (4)
Other Topic Rooms
- Gene Inheritance and Transmission
- Gene Expression and Regulation
- Nucleic Acid Structure and Function
- Chromosomes and Cytogenetics
- Evolutionary Genetics
- Population and Quantitative Genetics
- Genes and Disease
- Genetics and Society
- Cell Origins and Metabolism
- Proteins and Gene Expression
- Subcellular Compartments
- Cell Communication
- Cell Cycle and Cell Division
© 2014 Nature Education
- Press Room |
- Terms of Use |
- Privacy Notice |

Visual Browse
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
5.7 Protein Synthesis
Created by: CK-12/Adapted by Christine Miller
The Art of Protein Synthesis
This amazing artwork (Figure 5.7.1) shows a process that takes place in the cells of all living things: the production of proteins. This process is called protein synthesis , and it actually consists of two processes — transcription and translation . In eukaryotic cells, transcription takes place in the nucleus . During transcription, DNA is used as a template to make a molecule of messenger RNA ( mRNA ). The molecule of mRNA then leaves the nucleus and goes to a ribosome in the cytoplasm , where translation occurs. During translation, the genetic code in mRNA is read and used to make a polypeptide. These two processes are summed up by the central dogma of molecular biology: DNA → RNA → Protein .
Transcription
Transcription is the first part of the central dogma of molecular biology: DNA → RNA . It is the transfer of genetic instructions in DNA to mRNA. During transcription, a strand of mRNA is made to complement a strand of DNA. You can see how this happens in Figure 5.7.2.
Transcription begins when the enzyme RNA polymerase binds to a region of a gene called the promoter sequence. This signals the DNA to unwind so the enzyme can “read” the bases of DNA. The two strands of DNA are named based on whether they will be used as a template for RNA or not. The strand that is used as a template is called the template strand, or can also be called the a ntisense strand. The sequence of bases on the opposite strand of DNA is called the coding or sense strand. Once the DNA has opened, and RNA polymerase has attached, the RNA polymerase moves along the DNA, adding RNA nucleotides to the growing mRNA strand. The template strand of DNA is used as to create mRNA through complementary base pairing. Once the mRNA strand is complete, and it detaches from DNA. The result is a strand of mRNA that is nearly identical to the coding strand DNA – the only difference being that DNA uses the base thymine, and the mRNA uses uracil in the place of thymine
Processing mRNA
In eukaryotes , the new mRNA is not yet ready for translation. At this stage, it is called pre-mRNA, and it must go through more processing before it leaves the nucleus as mature mRNA. The processing may include splicing, editing, and polyadenylation. These processes modify the mRNA in various ways. Such modifications allow a single gene to be used to make more than one protein.
- Splicing removes introns from mRNA, as shown in Figure 5.7.3. Introns are regions that do not code for the protein. The remaining mRNA consists only of regions called exons that do code for the protein. The ribonucleoproteins in the diagram are small proteins in the nucleus that contain RNA and are needed for the splicing process.
- Editing changes some of the nucleotides in mRNA. For example, a human protein called APOB, which helps transport lipids in the blood, has two different forms because of editing. One form is smaller than the other because editing adds an earlier stop signal in mRNA.
- 5′ Capping adds a methylated cap to the “head” of the mRNA. This cap protects the mRNA from breaking down, and helps the ribosomes know where to bind to the mRNA
- Polyadenylation adds a “tail” to the mRNA. The tail consists of a string of As (adenine bases). It signals the end of mRNA. It is also involved in exporting mRNA from the nucleus, and it protects mRNA from enzymes that might break it down.
Translation
Translation is the second part of the central dogma of molecular biology: RNA → Protein . It is the process in which the genetic code in mRNA is read to make a protein . Translation is illustrated in Figure 5.7.4. After mRNA leaves the nucleus , it moves to a ribosome , which consists of rRNA and proteins. The ribosome reads the sequence of codons in mRNA, and molecules of tRNA bring amino acids to the ribosome in the correct sequence.
Translation occurs in three stages: Initiation, Elongation and Termination.
Initiation:
After transcription in the nucleus, the mRNA exits through a nuclear pore and enters the cytoplasm. At the region on the mRNA containing the methylated cap and the start codon, the small and large subunits of the ribosome bind to the mRNA. These are then joined by a tRNA which contains the anticodons matching the start codon on the mRNA. This group of molecues (mRNA, ribosome, tRNA) is called an initiation complex.
Elongation:
tRNA keep bringing amino acids to the growing polypeptide according to complementary base pairing between the codons on the mRNA and the anticodons on the tRNA. As a tRNA moves into the ribosome, its amino acid is transferred to the growing polypeptide. Once this transfer is complete, the tRNA leaves the ribosome, the ribosome moves one codon length down the mRNA, and a new tRNA enters with its corresponding amino acid. This process repeats and the polypeptide grows.
Termination :
At the end of the mRNA coding is a stop codon which will end the elongation stage. The stop codon doesn’t call for a tRNA, but instead for a type of protein called a release factor, which will cause the entire complex (mRNA, ribosome, tRNA, and polypeptide) to break apart, releasing all of the components.
Watch this video “Protein Synthesis (Updated) with the Amoeba Sisters” to see this process in action:
Protein Synthesis (Updated), Amoeba Sisters, 2018.
What Happens Next?
After a polypeptide chain is synthesized, it may undergo additional processes. For example, it may assume a folded shape due to interactions between its amino acids. It may also bind with other polypeptides or with different types of molecules, such as lipids or carbohydrates . Many proteins travel to the Golgi apparatus within the cytoplasm to be modified for the specific job they will do. 7 Summary
5.7 Summary
- Protein synthesis is the process in which cells make proteins. It occurs in two stages: transcription and translation.
- Transcription is the transfer of genetic instructions in DNA to mRNA in the nucleus. It includes three steps: initiation, elongation, and termination. After the mRNA is processed, it carries the instructions to a ribosome in the cytoplasm.
- Translation occurs at the ribosome, which consists of rRNA and proteins. In translation, the instructions in mRNA are read, and tRNA brings the correct sequence of amino acids to the ribosome. Then, rRNA helps bonds form between the amino acids, producing a polypeptide chain.
- After a polypeptide chain is synthesized, it may undergo additional processing to form the finished protein.
5.7 Review Questions
- Relate protein synthesis and its two major phases to the central dogma of molecular biology.
- Explain how mRNA is processed before it leaves the nucleus.
- What additional processes might a polypeptide chain undergo after it is synthesized?
- Where does transcription take place in eukaryotes?
- Where does translation take place?
5.7 Explore More
Protein Synthesis, Teacher’s Pet, 2014.
Attributions
Figure 5.7.1
How proteins are made by Nicolle Rager, National Science Foundation on Wikimedia Commons is released into the public domain (https://en.wikipedia.org/wiki/Public_domain) .
Figure 5.7.2
Transcription by National Human Genome Research Institute , (reworked and vectorized by Sulai) on Wikimedia Commons is released into the public domain (https://en.wikipedia.org/wiki/Public_domain) .
Figure 5.7.3
Pre mRNA processing by Christine Miller is used under a CC BY-NC-SA 4.0 (https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
Figure 5.7.4
Translation by CNX OpenStax on Wikimedia Commons is used under a CC BY 4.0 (https://creativecommons.org/licenses/by/4.0) license.
Amoeba Sisters. (2018, January 18) Protein synthesis (Updated). YouTube. https://www.youtube.com/watch?v=oefAI2x2CQM&feature=youtu.be
Parker, N., Schneegurt, M., Thi Tu, A-H., Lister, P., Forster, B.M. (2016, November 1). Microbiology [online]. Figure 11.15 Translation in bacteria begins with the formation of the initiation complex. In Microbiology (Section 11-4). OpenStax. https://openstax.org/books/microbiology/pages/11-4-protein-synthesis-translation
Teacher’s Pet. (2014, December 7). Protein synthesis. YouTube. https://www.youtube.com/watch?v=2zAGAmTkZNY&feature=youtu.be
The process of creating protein molecules.
The process by which DNA is copied (transcribed) to mRNA in order transfer the information needed for protein synthesis.
The process in which mRNA along with transfer RNA (tRNA) and ribosomes work together to produce polypeptides.
Cells which have a nucleus enclosed within membranes, unlike prokaryotes, which have no membrane-bound organelles.
A central organelle containing hereditary material.
Deoxyribonucleic acid - the molecule carrying genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses.
A large family of RNA molecules that convey genetic information from DNA to the ribosome, where they specify the amino acid sequence of the protein products of gene expression.
A large complex of RNA and protein which acts as the site of RNA translation, building proteins from amino acids using messenger RNA as a template.
The jellylike material that makes up much of a cell inside the cell membrane, and, in eukaryotic cells, surrounds the nucleus. The organelles of eukaryotic cells, such as mitochondria, the endoplasmic reticulum, and (in green plants) chloroplasts, are contained in the cytoplasm.
A nucleic acid of which many different kinds are now known, including messenger RNA, transfer RNA and ribosomal RNA.
A class of biological molecule consisting of linked monomers of amino acids and which are the most versatile macromolecules in living systems and serve crucial functions in essentially all biological processes.
The addition of a poly(A) tail to a messenger RNA. The poly(A) tail consists of multiple adenosine monophosphates.
A sequence of 3 DNA or RNA nucleotides that corresponds with a specific amino acid or stop signal during protein synthesis.
A small RNA molecule that participates in protein synthesis. Each tRNA molecule has two important areas: an anticodon and a region for attaching a specific amino acid.
Amino acids are organic compounds that combine to form proteins.
A substance that is insoluble in water. Examples include fats, oils and cholesterol. Lipids are made from monomers such as glycerol and fatty acids.
A biomolecule consisting of carbon (C), hydrogen (H) and oxygen (O) atoms, usually with a hydrogen–oxygen atom ratio of 2:1. Complex carbohydrates are polymers made from monomers of simple carbohydrates, also termed monosaccharides.
A membrane-bound organelle found in eukaryotic cells made up of a series of flattened stacked pouches with the purpose of collecting and dispatching protein and lipid products received from the endoplasmic reticulum (ER). Also referred to as the Golgi complex or the Golgi body.
Human Biology Copyright © 2020 by Christine Miller is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book
15.5 Ribosomes and Protein Synthesis
Learning objectives.
By the end of this section, you will be able to do the following:
- Describe the different steps in protein synthesis
- Discuss the role of ribosomes in protein synthesis
The synthesis of proteins consumes more of a cell’s energy than any other metabolic process. In turn, proteins account for more mass than any other component of living organisms (with the exception of water), and proteins perform virtually every function of a cell. The process of translation, or protein synthesis, involves the decoding of an mRNA message into a polypeptide product. Amino acids are covalently strung together by interlinking peptide bonds in lengths ranging from approximately 50 to more than 1000 amino acid residues. Each individual amino acid has an amino group (NH 2 ) and a carboxyl (COOH) group. Polypeptides are formed when the amino group of one amino acid forms an amide (i.e., peptide) bond with the carboxyl group of another amino acid ( Figure 15.15 ). This reaction is catalyzed by ribosomes and generates one water molecule.
The Protein Synthesis Machinery
In addition to the mRNA template, many molecules and macromolecules contribute to the process of translation. The composition of each component may vary across species; for example, ribosomes may consist of different numbers of rRNAs and polypeptides depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors. (Note: A ribosome can be thought of as an enzyme whose amino acid binding sites are specified by mRNA.)
Link to Learning
Click through the steps of this PBS interactive to see protein synthesis in action.
Even before an mRNA is translated, a cell must invest energy to build each of its ribosomes. In E. coli , there are between 10,000 and 70,000 ribosomes present in each cell at any given time. A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. In eukaryotes, the nucleolus is completely specialized for the synthesis and assembly of rRNAs.
Ribosomes exist in the cytoplasm of prokaryotes and in the cytoplasm and rough endoplasmic reticulum of eukaryotes. Mitochondria and chloroplasts also have their own ribosomes in the matrix and stroma, which look more similar to prokaryotic ribosomes (and have similar drug sensitivities) than the ribosomes just outside their outer membranes in the cytoplasm. Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation. In E. coli, the small subunit is described as 30S, and the large subunit is 50S, for a total of 70S (recall that Svedberg units are not additive). Mammalian ribosomes have a small 40S subunit and a large 60S subunit, for a total of 80S. The small subunit is responsible for binding the mRNA template, whereas the large subunit sequentially binds tRNAs. Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction: reading the mRNA from 5' to 3' and synthesizing the polypeptide from the N terminus to the C terminus. The complete mRNA/poly-ribosome structure is called a polysome .
The tRNAs are structural RNA molecules that were transcribed from genes by RNA polymerase III. Depending on the species, 40 to 60 types of tRNAs exist in the cytoplasm. Transfer RNAs serve as adaptor molecules. Each tRNA carries a specific amino acid and recognizes one or more of the mRNA codons that define the order of amino acids in a protein. Aminoacyl-tRNAs bind to the ribosome and add the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins.
Of the 64 possible mRNA codons—or triplet combinations of A, U, G, and C—three specify the termination of protein synthesis and 61 specify the addition of amino acids to the polypeptide chain. Of these 61, one codon (AUG) also encodes the initiation of translation. Each tRNA anticodon can base pair with one or more of the mRNA codons for its amino acid. For instance, if the sequence CUA occurred on an mRNA template in the proper reading frame, it would bind a leucine tRNA expressing the complementary sequence, GAU. The ability of some tRNAs to match more than one codon is what gives the genetic code its blocky structure.
As the adaptor molecules of translation, it is surprising that tRNAs can fit so much specificity into such a small package. Consider that tRNAs need to interact with three factors: 1) they must be recognized by the correct aminoacyl synthetase (see below); 2) they must be recognized by ribosomes; and 3) they must bind to the correct sequence in mRNA.
Aminoacyl tRNA Synthetases
The process of pre-tRNA synthesis by RNA polymerase III only creates the RNA portion of the adaptor molecule. The corresponding amino acid must be added later, once the tRNA is processed and exported to the cytoplasm. Through the process of tRNA “charging,” each tRNA molecule is linked to its correct amino acid by one of a group of enzymes called aminoacyl tRNA synthetases . At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids; the exact number of aminoacyl tRNA synthetases varies by species. These enzymes first bind and hydrolyze ATP to catalyze a high-energy bond between an amino acid and adenosine monophosphate (AMP); a pyrophosphate molecule is expelled in this reaction. The activated amino acid is then transferred to the tRNA, and AMP is released. The term "charging" is appropriate, since the high-energy bond that attaches an amino acid to its tRNA is later used to drive the formation of the peptide bond. Each tRNA is named for its amino acid.
The Mechanism of Protein Synthesis
As with mRNA synthesis, protein synthesis can be divided into three phases: initiation, elongation, and termination . The process of translation is similar in prokaryotes and eukaryotes. Here we’ll explore how translation occurs in E. coli , a representative prokaryote, and specify any differences between prokaryotic and eukaryotic translation.
Initiation of Translation
Protein synthesis begins with the formation of an initiation complex . In E. coli , this complex involves the small 30S ribosome, the mRNA template, three initiation factors (IFs; IF-1, IF-2, and IF-3), and a special initiator tRNA , called tRNA fMet .
In E. coli mRNA, a sequence upstream of the first AUG codon, called the Shine-Dalgarno sequence (AGGAGG), interacts with the rRNA molecules that compose the ribosome. This interaction anchors the 30S ribosomal subunit at the correct location on the mRNA template. Guanosine triphosphate (GTP), which is a purine nucleotide triphosphate, acts as an energy source during translation—both at the start of elongation and during the ribosome’s translocation. Binding of the mRNA to the 30S ribosome also requires IF-3.
The initiator tRNA then interacts with the start codon AUG (or rarely, GUG). This tRNA carries the amino acid methionine, which is formylated after its attachment to the tRNA. The formylation creates a "faux" peptide bond between the formyl carboxyl group and the amino group of the methionine. Binding of the fMet-tRNA fMet is mediated by the initiation factor IF-2. The fMet begins every polypeptide chain synthesized by E. coli , but it is usually removed after translation is complete. When an in-frame AUG is encountered during translation elongation, a non-formylated methionine is inserted by a regular Met-tRNA Met . After the formation of the initiation complex, the 30S ribosomal subunit is joined by the 50S subunit to form the translation complex. In eukaryotes, a similar initiation complex forms, comprising mRNA, the 40S small ribosomal subunit, eukaryotic IFs, and nucleoside triphosphates (GTP and ATP). The methionine on the charged initiator tRNA, called Met-tRNA i , is not formylated. However, Met-tRNA i is distinct from other Met-tRNAs in that it can bind IFs.
Instead of depositing at the Shine-Dalgarno sequence, the eukaryotic initiation complex recognizes the 7-methylguanosine cap at the 5' end of the mRNA. A cap-binding protein (CBP) and several other IFs assist the movement of the ribosome to the 5' cap. Once at the cap, the initiation complex tracks along the mRNA in the 5' to 3' direction, searching for the AUG start codon. Many eukaryotic mRNAs are translated from the first AUG, but this is not always the case. According to Kozak’s rules , the nucleotides around the AUG indicate whether it is the correct start codon. Kozak’s rules state that the following consensus sequence must appear around the AUG of vertebrate genes: 5'-gccRccAUGG-3'. The R (for purine) indicates a site that can be either A or G, but cannot be C or U. Essentially, the closer the sequence is to this consensus, the higher the efficiency of translation.
Once the appropriate AUG is identified, the other proteins and CBP dissociate, and the 60S subunit binds to the complex of Met-tRNA i , mRNA, and the 40S subunit. This step completes the initiation of translation in eukaryotes.
Translation, Elongation, and Termination
In prokaryotes and eukaryotes, the basics of elongation are the same, so we will review elongation from the perspective of E. coli . When the translation complex is formed, the tRNA binding region of the ribosome consists of three compartments. The A (aminoacyl) site binds incoming charged aminoacyl tRNAs. The P (peptidyl) site binds charged tRNAs carrying amino acids that have formed peptide bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E (exit) site releases dissociated tRNAs so that they can be recharged with free amino acids. The initiating methionyl-tRNA, however, occupies the P site at the beginning of the elongation phase of translation in both prokaryotes and eukaryotes.
During translation elongation, the mRNA template provides tRNA binding specificity. As the ribosome moves along the mRNA, each mRNA codon comes into register, and specific binding with the corresponding charged tRNA anticodon is ensured. If mRNA were not present in the elongation complex, the ribosome would bind tRNAs nonspecifically and randomly.
Elongation proceeds with charged tRNAs sequentially entering and leaving the ribosome as each new amino acid is added to the polypeptide chain. Movement of a tRNA from A to P to E site is induced by conformational changes that advance the ribosome by three bases in the 3' direction. The energy for each step along the ribosome is donated by elongation factors that hydrolyze GTP. GTP energy is required both for the binding of a new aminoacyl-tRNA to the A site and for its translocation to the P site after formation of the peptide bond. Peptide bonds form between the amino group of the amino acid attached to the A-site tRNA and the carboxyl group of the amino acid attached to the P-site tRNA. The formation of each peptide bond is catalyzed by peptidyl transferase , an RNA-based enzyme that is integrated into the 50S ribosomal subunit. The energy for each peptide bond formation is derived from the high-energy bond linking each amino acid to its tRNA. After peptide bond formation, the A-site tRNA that now holds the growing peptide chain moves to the P site, and the P-site tRNA that is now empty moves to the E site and is expelled from the ribosome ( Figure 15.18 ). Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200-amino-acid protein can be translated in just 10 seconds.
Visual Connection
Many antibiotics inhibit bacterial protein synthesis. For example, tetracycline blocks the A site on the bacterial ribosome, and chloramphenicol blocks peptidyl transfer. What specific effect would you expect each of these antibiotics to have on protein synthesis?
Tetracycline would directly affect:
- tRNA binding to the ribosome
- ribosome assembly
- growth of the protein chain
Chloramphenicol would directly affect:
Termination of translation occurs when a nonsense codon (UAA, UAG, or UGA) is encountered. Upon aligning with the A site, these nonsense codons are recognized by protein release factors that resemble tRNAs. The releasing factors in both prokaryotes and eukaryotes instruct peptidyl transferase to add a water molecule to the carboxyl end of the P-site amino acid. This reaction forces the P-site amino acid to detach from its tRNA, and the newly made protein is released. The small and large ribosomal subunits dissociate from the mRNA and from each other; they are recruited almost immediately into another translation initiation complex. After many ribosomes have completed translation, the mRNA is degraded so the nucleotides can be reused in another transcription reaction.
Protein Folding, Modification, and Targeting
During and after translation, individual amino acids may be chemically modified, signal sequences appended, and the new protein “folded” into a distinct three-dimensional structure as a result of intramolecular interactions. A signal sequence is a short sequence at the amino end of a protein that directs it to a specific cellular compartment. These sequences can be thought of as the protein’s “train ticket” to its ultimate destination, and are recognized by signal-recognition proteins that act as conductors. For instance, a specific signal sequence terminus will direct a protein to the mitochondria or chloroplasts (in plants). Once the protein reaches its cellular destination, the signal sequence is usually clipped off.
Many proteins fold spontaneously, but some proteins require helper molecules, called chaperones , to prevent them from aggregating during the complicated process of folding. Even if a protein is properly specified by its corresponding mRNA, it could take on a completely dysfunctional shape if abnormal temperature or pH conditions prevent it from folding correctly.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/biology-2e/pages/1-introduction
- Authors: Mary Ann Clark, Matthew Douglas, Jung Choi
- Publisher/website: OpenStax
- Book title: Biology 2e
- Publication date: Mar 28, 2018
- Location: Houston, Texas
- Book URL: https://openstax.org/books/biology-2e/pages/1-introduction
- Section URL: https://openstax.org/books/biology-2e/pages/15-5-ribosomes-and-protein-synthesis
© Sep 19, 2024 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
IMAGES
VIDEO